目录
1. Python3处理Json的函数
1.1 Python3 字符串转Json格式
1.2 json.dump函数与json.dumps函数的区别
1.3 Python json序列化自定义类
1.4 Python str函数与repr函数
2. Python类属性
2.1 Python中dir()与__dict__的区别
2.2 __import__函数
2.3 其他属性
3. Python list转str
4. Python os模块
5. Django中与manage.py有关的命令
6. Python math库,random库,pickle库
7. Python遍历文件夹
8. Python dict字典用法及其他
9. Reference
1. Python3处理Json的函数
在使用json模块的相关函数时需要先使用import json 该语句将json模块导入进来。
在python命令行中输入dir(json)命令可以看到json模块提供的各种属性,即:
['JSONDecodeError', 'JSONDecoder', 'JSONEncoder', '__all__',
'__author__', '__builtins__', '__cached__', '__doc__', '__file__',
'__loader__', '__name__', '__package__', '__path__', '__spec__',
'__version__', '_default_decoder', '_default_encoder', 'decoder',
'dump', 'dumps', 'encoder', 'load', 'loads', 'scanner']
1.1 Python3 字符串转Json格式
将python字符串转换成json格式,需要使用json.dumps函数。
但是需要注意,有时候一不小心就会把json.dumps函数写成json.dump。比如以下示例:
data = [{"a":"aaa","b":"bbb","c":[1,2,3,(4,5,6)]},33,'tantengvip',True]
data2 = json.dump(data)这样写会报错:TypeError: dump() missing 1 required positional argument: 'fp'
因此我们需要注意:json.dump和json.dumps两个函数的区别。
1.2 json.dump函数与json.dumps函数的区别
json.dump和json.dumps两个函数的作用是不相同的。json.dump用来json文件读写,和json.load函数配合使用。函数调用格式为json.dump(x,f),其中x为对象,f是一个文件对象,这个方法可以将json字符串写入到文本文件中。例如:
import json
data = [{"a":"aaa","b":"bbb","c":[1,2,3,(4,5,6)]},33,'tantengvip',True]
f = open('json.txt','a')
json.dump(data,f) 在这个代码片段中,通过json.dumps函数将python的list列表通过json.dump函数转换成json字符串并写入文件。json.dump也可以将json字符串写入文件,如果不是json字符串,则会在函数内部进行自动转化。
json.load函数可以用来加载json格式的文件
f = open('json.txt','r')
text = json.load(f)该函数会读取文件中的json字符串,并将其转换成python对象并返回结果。此后,我们就可以直接对python对象进行操作。
json.load函数与下面的代码意思相同:
f = open('json.txt','r')
text = f.read()
py_text = json.loads(text)text是读取文件得到的json字符串,通过json.loads函数将json字符串转换为python对象。
json.dumps函数可以对python对象进行编码,转换为json字符串。例如:
import json
obj = [[1,2,3],123,123.123,'abc',{'key1':(1,2,3),'key2':(4,5,6)}]
encodedjson = json.dumps(obj)
print(repr(obj))
print(encodedjson)输出结果如下:
[[1, 2, 3], 123, 123.123, 'abc', {'key2': (4, 5, 6), 'key1': (1, 2, 3)}]
[[1, 2, 3], 123, 123.123, "abc", {"key2": [4, 5, 6], "key1": [1, 2, 3]}]
通过输出的结果可以看出,简单类型通过encode之后跟其原始的repr()输出结果非常相似,但是有些数据类型进行了改变,例如上例中的元组则转换为了列表。在json的编码过程中,会存在从python原始类型向json类型的转化过程,具体的转化对照如下:
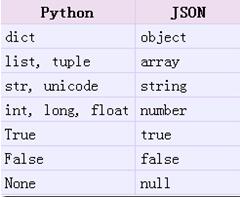
注意,在将python的对象转换成json字符串时
- True变成了true
- 元组tuple的圆括号()变成了json中的Array的方括号[],即python中tuple的()和list的[]转成json时都会变成[]
- json字符串中只能用双引号,不能用单引号!!!
- json字符串中的Array的最后一个元素后面不能加逗号’,’,即python的list最后一个元素后不要多加逗号
- json字符串中的Object的最后一个属性后面不能加逗号’,’,即python的dict中的最后一个属性后不要多加逗号
json.dumps()方法返回了一个str对象encodedjson,我们接下来在对encodedjson进行decode,得到原始数据,需要使用的json.loads()函数:
import json
obj = [[1,2,3],123,123.123,'abc',{'key1':(1,2,3),'key2':(4,5,6)}]
encodedjson = json.dumps(obj)
decodejson = json.loads(encodedjson)
print(type(decodejson))
print(decodejson[4]['key1'])
print(decodejson) 输出结果如下:
<type 'list'>
[1, 2, 3]
[[1, 2, 3], 123, 123.123, u'abc', {u'key2': [4, 5, 6], u'key1': [1, 2, 3]}]
json.loads方法返回了原始的对象,但是仍然发生了一些数据类型的转化。比如,上例中’abc’转化为了unicode类型。从json到python的类型转化对照如下:
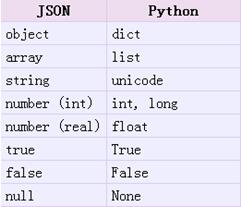
data1 = {'b':789,'c':456,'a':123}
data2 = {'a':123,'b':789,'c':456}
d1 = json.dumps(data1,sort_keys=True)
d2 = json.dumps(data2)
d3 = json.dumps(data2,sort_keys=True)
print(d1)
print(d2)
print(d3)
print(d1==d2)
print(d1==d3) 输出结果如下:
{"a": 123, "b": 789, "c": 456}
{"a": 123, "c": 456, "b": 789}
{"a": 123, "b": 789, "c": 456}
False
True
indent参数是缩进的意思,它可以使得数据存储的格式变得更加优雅。
data1 = {'b':789,'c':456,'a':123}
d1 = json.dumps(data1,sort_keys=True,indent=4)
print(d1) 输出:
{
"a": 123,
"b": 789,
"c": 456
}
输出的数据被格式化之后,变得可读性更强,但是却是通过增加一些冗余的空白格来进行填充的。
json主要是作为一种数据通信的格式存在的,而网络通信是很在乎数据的大小的,无用的空格会占据很多通信带宽,所以适当时候也要对数据进行压缩。separator参数可以起到这样的作用,该参数传递是一个元组,包含分割对象的字符串。
data = {'b':789,'c':456,'a':123}
print('DATA:', repr(data))
print('repr(data):', len(repr(data)))
print('DATA:', json.dumps(data))
print('dumps(data):', len(json.dumps(data)))
print('DATA:', json.dumps(data, indent=4))
print('dumps(data, indent=4):', len(json.dumps(data, indent=4)))
print('DATA:', json.dumps(data, separators=(',',':')))
print('dumps(data, separators):', len(json.dumps(data, separators=(',',':'))))输出:
DATA: {'c': 456, 'b': 789, 'a': 123}
repr(data): 30
DATA: {"c": 456, "b": 789, "a": 123}
dumps(data): 30
DATA: {
"c": 456,
"b": 789,
"a": 123
}
dumps(data, indent=4): 44
DATA: {"c":456,"b":789,"a":123}
dumps(data, separators): 25
通过移除多余的空白符,达到了压缩数据的目的,而且效果还是比较明显的。
另一个比较有用的json.dumps函数的参数是skipkeys,默认为False。 dumps方法存储dict对象时,key必须是str类型,如果出现了其他类型的话,那么会产生TypeError异常,如果开启该参数,设为True的话,则会跳过非法的key。例如:
data = {'b':789,'c':456,(1,2):123}
print json.dumps(data,skipkeys=True)输出:
{"c": 456, "b": 789}
1.3 Python json序列化自定义类
json模块不仅可以处理普通的python内置类型,也可以处理我们自定义的数据类型,而往往处理自定义的对象是很常用的。
首先,我们定义一个类Person。
class Person(object):
def __init__(self,name,age):
self.name = name
self.age = age
def __repr__(self):
return 'Person Object name : %s , age : %d' % (self.name,self.age)
if __name__ == '__main__':
p = Person('Peter',22)
print p如果直接通过json.dumps方法对Person的实例进行处理的话,会报错,因为json无法支持这样的自动转化。通过上面所提到的json和python的类型转化对照表,可以发现,object类型是和dict相关联的,所以我们需要把我们自定义的类型转化为dict,然后再进行处理。这里,有两种方法可以使用。
方法一:自己写转化函数
import Person
import json
p = Person.Person('Peter',22)
def object2dict(obj):
#convert object to a dict
d = {}
d['__class__'] = obj.__class__.__name__
d['__module__'] = obj.__module__
d.update(obj.__dict__) #更新dict的内容
return d
def dict2object(d):
#convert dict to object
if '__class__' in d :
class_name = d.pop('__class__')
module_name = d.pop('__module__')
module = __import__(module_name)
class_ = getattr(module,class_name)
args = dict((key.encode('ascii'), value) for key, value in d.items()) #get args
inst = __new__(**args) #create new instance
else :
inst = d
return inst
d = object2dict(p)
print(d)
#{'age': 22, '__module__': 'Person', '__class__': 'Person', 'name': 'Peter'}
o = dict2object(d)
print(type(o),o)
#<class 'Person.Person'> Person Object name : Peter , age : 22
dump = json.dumps(p,default=object2dict)
print dump
#{"age": 22, "__module__": "Person", "__class__": "Person", "name": "Peter"}
load = json.loads(dump,object_hook = dict2object)
print load
#Person Object name : Peter , age : 22上面代码已经写的很清楚了,实质就是自定义object类型和dict类型进行转化。object2dict函数将对象模块名、类名以及__dict__存储在dict对象里,并返回。dict2object函数则是反解出模块名、类名、参数,创建新的对象并返回。在json.dumps方法中增加default参数,该参数表示在转化过程中调用指定的函数,同样在decode过程中json.loads方法增加object_hook,指定转化函数。
方法二:继承JSONEncoder和JSONDecoder类,覆写相关方法
JSONEncoder类负责编码,主要是通过其default函数进行转化,我们可以override该方法。同理对于JSONDecoder。
import Person
import json
p = Person.Person('Peter',22)
class MyEncoder(json.JSONEncoder):
def default(self,obj):
#convert object to a dict
d = {}
d['__class__'] = obj.__class__.__name__
d['__module__'] = obj.__module__
d.update(obj.__dict__)
return d
class MyDecoder(json.JSONDecoder):
def __init__(self):
json.JSONDecoder.__init__(self,object_hook=self.dict2object)
def dict2object(self,d):
#convert dict to object
if'__class__' in d :
class_name = d.pop('__class__')
module_name = d.pop('__module__')
module = __import__(module_name)
class_ = getattr(module,class_name)
args = dict((key.encode('ascii'), value) for key, value in d.items()) #get args
inst = __new__(**args) #create new instance
else :
inst = d
return inst
d = MyEncoder().encode(p)
o = MyDecoder().decode(d)
print d
print type(o), o在以上代码中,类的参数即为继承的父类。
1.4 Python str函数与repr函数
Python有办法将任意值转为字符串:将它传入repr() 或str() 函数。 函数str() 用于将值转化为适于人阅读的形式,而repr() 转化为供解释器读取的形式。(如果没有等价的语法,则会发生SyntaxError 异常) 某对象没有适于人阅读的解释形式的话, str() 会返回与repr()等同的值。很多类型,诸如数值或链表、字典这样的结构,针对各函数都有着统一的解读方式。)
字符串和浮点数有着独特的解读方式。
>>> s = 'Hello, world.'
>>> str(s)
'Hello, world.'
>>> repr(s)
"'Hello, world.'"
>>> str(1.0/7.0)
'0.142857142857'
>>> repr(1.0/7.0)
'0.14285714285714285'
2. Python类属性
2.1 Python中dir()与__dict__的区别
要知道一个类有哪些属性,有两种方法。最简单的是使用 dir() 内建函数。另外是通过访问类的字典属性 __dict__。
类和实例都有__dict__属性,不过内容有所不同。
>>> class MyClass(object):
... def myNoActionMethod(self):
... pass
...
>>> mc = MyClass()
>>> mc.myNoActionMethod()
>>> dir(MyClass)
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__form
at__',
'__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__',
'__module__', '__ne__', '__new__', '__qualname__', '__reduce__', '__reduce_ex__', '__repr__',
'__setattr__', '__sizeof__', '__str__', '__subclasshook
__', '__weakref__', 'myVersion',
'showMyVersion']
>>> MyClass.__dict__
mappingproxy({'__module__': '__main__', '__qualname__': 'MyClass', '__weakref__'
: <attribute '__weakref__' of 'MyClass' objects>, 'showMyVersion': <function MyC
lass.showMyVersion at 0x01D98F18>, '__dict__': <attribute '__dict__' of 'MyClass
' objects>,
'myVersion': '1.1', '__doc__': 'MyClass class definition'}) dir() 返回的仅是对象的属性的一个名字类表,而 __dict__ 返回的是一个字典,它的键(key)是属性名,键值(value)是相应的属性对象的数据值。
内建函数 dir() 可以显示类属性,同样还可以打印所有实例属性:
>>> class C():
... pass
...
>>> c = C()
>>> c.foo = 'roger'
>>> c.bar = 'shrubber'
>>> dir(c)
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__form
at__',
'__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__le__', '__lt__',
'__module__', '__ne__', '__new__', '__qualname__', '__reduce__', '__r
educe_ex__', '__repr__',
'__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'bar', 'foo'] 实例也有一个 __dict__特殊属性,它是实例属性构成的一个字典:
>>> c.__dict__
{'foo': 'roger', 'bar': 'shrubber'} __dict__函数的巧妙使用可以减少构造对象时的大量赋值代码。例子如下:
class Person:
def __init__(self,_obj):
self.name = _obj['name']
self.age = _obj['age']
self.energy = _obj['energy']
self.gender = _obj['gender']
self.email = _obj['email']
self.phone = _obj['phone']
self.country = _obj['country'] 使用__dict__函数可以简化代码:
class Person:
def __init__(self,_obj):
self.__dict__.update(_obj)不是所有的对象都有__dict__属性。例如,如果你在一个类中添加了__slots__属性,那么这个类的实例将不会拥有__dict__属性,但是dir()仍然可以找到并列出它的实例所有有效属性。(__slots__属性详解见Python学习笔记(二))
2.2 __import__函数
使用__import__函数可以在程序中动态调用模块或模块中的函数。如果我们知道模块的名称(字符串)的时候,我们可以很方便地使用动态调用。
import关键字可以导入/引入一个python标准模块,其中包括.py文件,带有__init__.py文件的目录。
__import__函数的作用和import关键字的作用一样,只是__import__函数只能接收字符串作为参数
import sys相当于sys = __import__('sys'),如果要导入类似package.function的函数时,不能直接用mod = __import('package.function')的形式来导入该模块。参考官方文档:
When the name variable is of the form package.module, normally, the top-level package(the name up till the first dot) is returned,not the module named by name. However, when a non-empty from list argument is given(真的只要不是空就可以了,你可以随便写,比如[“a”]), the module named by name is returned. This is done for compatibility with the bytecode generated for the different kinds of import statement; when using import spam.ham.eggs, the top-level package spam must be placed in the importing namespace, but when using from spam.ham import eggs, the spam.ham subpackage must be used to find the eggs variable. As a workaround for this behavior, use getattr() to extract the desired components. For example, you could define the following helper:
def my_import(name):
mod = __import__(name)
components = name.split('.')
for comp in components[1:]:
mod = getattr(mod, comp)
return mod
2.3 其他属性
-
__init__属性
对象生命周期的基础是创建、初始化和销毁。__init__方法在类的一个对象被建立时,马上运行。这个方法可以用来对你的对象做一些你希望的初始化。
__init__()方法意义重大的原因有两个。第一个原因是在对象生命周期中初始化是最重要的一步;每个对象必须正确初始化后才能正常工作。第二个原因是__init__()参数值可以有多种形式。
python中的object类是一个隐含的超类,每一个python类都隐含了object这个超类。例如:class X: pass >>> X.__class__ <class 'type'> >>> X.__class__.__base__ <class 'object'> -
__class__属性
使用C.__class__属性可以获得该实例C对应的类。
对象的__class__属性指明了对象所属的类型。
>>> [].__class__
<class 'list'>
>>> ().__class__
<class 'tuple'>
>>> 1.__class__
File "<stdin>", line 1
1.__class__
^
SyntaxError: invalid syntax
>>> type(1)
<class 'int'>python的super()方法和__class__的关系见Python学习笔记(二))
-
__name__属性
C.__name__属性可以返回类C的名字(字符串),__name__是给定类的字符名字。它适用于那种只需要字符串(类对象的名字),而非对象本身的情况。 -
__doc__属性
C.__doc__属性是类的文档字符串,与函数及模块的文档字符串相似,必须紧随头行后的字符串。文档字符串不能被派生类继承,也就是说派生类必须含有他们自己的文档字符串。 -
__bases__属性
C.__bases__用来处理继承,它包含了一个由所有父类组成的元组。python中每个类都有一个__base__属性,例如:
>>> class Base:
... pass
...
>>> class Derived(Base):
... pass
>>> Derived.__bases__
(<class '__main__.Base'>,)
>>> class Derived2(Derived,Base):
... pass
>>> Derived2.__bases__
(<class '__main__.Derived'>, <class '__main__.Base'>)python和C++一样,也支持多重继承,注意,在这里父类Derived和Base的顺序不能搞反了。否则会出现以下错误:
>>> class Derived2(Base, Derived):
... pass
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Cannot create a consistent method resolution
order (MRO) for bases Derived, Base注意:__base__属性是类的属性,不是对象的属性
>>> d = Derived2()
>>> d.__bases__
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Derived2' object has no attribute '__bases__'
>>> d.__class__
<class '__main__.Derived2'>
>>> d.__class__.__bases__
(<class '__main__.Derived'>, <class '__main__.Base'>)- __new__属性
继承自object的新式类才有
__new__属性。
__new__属性至少要有一个参数cls,代表要实例化的类,此参数在实例化时由Python解释器自动提供。
__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类__new__出来的实例,或者直接是object的__new__出来的实例。
__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值。 若__new__没有正确返回当前类cls的实例,那__init__是不会被调用的,即使是父类的实例也不行。
class A(object):
pass
class B(A):
def __init__(self):
print "init"
def __new__(cls,*args, **kwargs):
print "new %s"%cls
return object.__new__(A, *args, **kwargs)
b=B()
print type(b)输出结果如下:
new <class '__main__.B'>
<class '__main__.A'>
- __del__属性
在一个类的实例被删除时调用该方法
3. Python list转str
在Python中将list转成str,可以用json.dumps()来将list转成json字符串。除此之外,也可以用str的join函数。在使用’‘.join()时保证参数的内容为str,如果参数是非str,如下所示:
List = [1,[2,3,4],3,4,5]
str_convert = ''.join(List)
print(str_convert)输出结果为:
TypeError: sequence item 0: expected str instance, int found
因此,如果join的参数是list,则list中的元素必须都是str才行。例如:
str = 'abcde'
List = list(str)
print(List)
print(str)
str_convert = ''.join(List)
print(str_convert)输出结果为:
['a', 'b', 'c', 'd', 'e']
abcde
abcde
4. Python os模块
在Python中可以方便地使用os模块运行其他的脚本或者程序,这样就可以在脚本中直接使用其他脚本,或者程序提供的功能,而不必再次编写实现该功能的代码。为了更好地控制运行的进程,可以使用win32process模块中的函数。如果想进一步控制进程,则可以使用ctype模块,直接调用kernel32.dll中的函数。
-
使用os.system函数运行其他程序 os模块中的system()函数可以方便地运行其他程序或者脚本。其函数原型如下所示:
os.system(command),其参数含义如下所示。command要执行的命令,相当于在Windows的cmd窗口中输入的命令。如果要向程序或者脚本传递参数,可以使用空格分隔程序及多个参数。例如:
import os # 使用os.system()函数打开记事本程序 os.system('notepad') # 向记事本传递参数,打开python.txt文件 os.system('notepad python.txt') -
os.name:输出字符串指示正在使用的平台。如果是window 则用’nt’表示,对于Linux/Unix用户,它是’posix’。
-
os.getcwd():得到当前工作目录,即当前Python脚本工作的目录路径。
-
os.listdir():返回指定目录下的所有文件和目录名。
-
os.remove():删除一个文件。
-
os.system():运行shell命令。
-
os.sep:可以取代操作系统特定的路径分割符。
-
os.linesep:用字符串给出当前平台使用的行终止符。
-
os.path.split():该函数返回一个路径的目录名和文件名。
os.path.split('C:\\Python25\\abc.txt')输出结果为:
('C:\\Python25', 'abc.txt') -
os.path.isfile(),os.path.isdir():它们分别检验给出的路径是一个文件还是目录。
-
os.path.exists():用来检验给出的路径是否真地存在。
-
os.path.abspath(name):获得绝对路径。
-
os.path.normpath(path):规范path字符串形式。
-
os.path.getsize(name):获得文件大小,如果name是目录返回0L。
-
os.path.splitext():分离文件名与扩展名。
os.path.splitext('a.txt')输出结果为:
('a', '.txt') -
os.path.join(path,name):连接目录与文件名或目录。
os.path.join('c:\\Python','a.txt') os.path.join('c:\\Python','f1')输出结果为:
'c:\\Python\\a.txt' 'c:\\Python\\f1' -
os.path.basename(path):返回文件名。
os.path.basename('a.txt') os.path.basename('c:\\Python\\a.txt')输出结果为:
'a.txt' 'a.txt' -
os.path.dirname(path):返回文件路径。
os.path.dirname('c:\\Python\\a.txt')输出结果为:
'c:\\Python'
5. Django中与manage.py有关的命令
django-admin.py startproject mysite 该命令在当前目录创建一个 mysite 目录。 django-admin.py这个文件在C:\Python27\Lib\site-packages\django\bin文件夹里,可以把该目录添加到系统Path里面。 Django内置一个轻量级的Web服务器。 进入 mysite 目录的话,现在进入其中,并运行 python manage.py runserver 命令 启动服务器,用http://127.0.0.1:8000/可以进行浏览了,8000是默认的端口号。
-
python manage.py runserver 8080:更改服务器端口号。 -
python manage.py shell:启动交互界面。 -
python manage.py startapp books:创建一个app,名为books。 -
python manage.py validate:验证Django数据模型代码是否有错误。 -
python manage.py sqlall books:为模型产生sql代码。 -
python manage.py sqlmigrate:用来把数据库迁移文件转换成数据库语言(displays the SQL statements for a migratioin)。
用法:python manage.py sqlmigrate app migration,比如makemigrations生成了0001_initial.py,就用sqlmigrate app 0001_intial,这里0001_initial就是migration参数。 -
python manage.py dbshell:启动数据库的命令行工具。 -
manage.py sqlall books:查看books这个app下所有的表。 -
python manage.py makemigrations:用来检测数据库变更和生成数据库迁移文件。 -
python manage.py migrate:用来迁移数据库。
6. Python math库,random库,pickle库
python的math库定义了两个常数:
math.e # 自然常数e
math.pi # 圆周率pi
还有一些运算函数:
-
math.ceil(x)表示对x向上取整,比如x=1.2,返回2 -
math.floor(x)表示对x向下取整,比如x=1.2,返回1 -
math.pow(x,y)表示指数运算,得到x的y次方 -
math.log(x)表示求对数,默认基底为e。可以使用base参数,来改变对数的基地。比如math.log(100,base=10) -
math.sqrt(x)表示求平方根 -
三角函数:
math.sin(x),math.cos(x),math.tan(x),math.asin(x),math.acos(x),math.atan(x) -
角度和弧度互换:
math.degrees(x),math.radians(x) -
双曲函数:
math.sinh(x),math.cosh(x),math.tanh(x),math.asinh(x),math.acosh(x),math.atanh(x) -
特殊函数:
math.erf(x),math.gamma(x)
python random库中的常见函数如下:
random.seed(x)用来改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。
1) 随机挑选和排序
-
random.choice(seq):从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 -
random.sample(seq,k):从序列中随机挑选k个元素 -
random.shuffle(seq):将序列的所有元素随机排序
2)随机生成实数
下面生成的实数符合均匀分布(uniform distribution),意味着某个范围内的每个数字出现的概率相等:
-
random.random():随机生成下一个实数,它在[0,1)范围内。 -
random.uniform(a,b):随机生成下一个实数,它在[a,b]范围内。 -
random.gauss(mu,sigma): 随机生成符合高斯分布的随机数,mu,sigma为高斯分布的两个参数。 -
random.expovariate(lambd):随机生成符合指数分布的随机数,lambd为指数分布的参数。
python pickle模块 pickle提供了一个简单的持久化功能。可以将对象以文件的形式存放在磁盘上。
pickle.dump(obj, file[, protocol])用来序列化对象,并将结果数据流写入到文件对象中。参数protocol是序列化模式,默认值为0,表示以文本的形式序列化。protocol的值还可以是1或2,表示以二进制的形式序列化。protocol的值为-1也可以通过二进制形式序列化。
pickle.load(file)用来反序列化对象。将文件中的数据解析为一个Python对象。
7. Python遍历文件夹
python遍历一个文件夹下的所有文件用以下函数实现:
for parent,dirnames,filenames in os.walk(rootdir):
for dirname in dirnames: #输出文件夹信息
print("parent is:" + parent)
print("dirname is" + dirname)
for filename in filenames: #输出文件信息
print("parent is": + parent)
print("filename is:" + filename)
#输出文件路径信息
print("the full name of the file is:" + os.path.join(parent,filename))该函数的for循环时有三个参数,os.walk分别返回:
- 父目录
- 所有文件夹名字(不含路径)
- 所有文件名字
8. Python dict字典用法及其他
- 向字典中添加元素
info = {}
info['name'] = 'jay'
info['age'] = 20
info['python'] = 'hahaha'
printf(info)
#{'name':'jay','age':20,'python':'hahaha'}- 从字典中取元素
info = {}
info['name'] = 'jay'
info['age'] = 20
info['python'] = 'hahaha'
printf(info['a'])从字典中取某个key对应的value,可以直接用dict[key]来去元素,但是就上面的例子而言,由于info中没有’a’这个key,所以运行后会报错:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'a'
提示说程序中出现了KeyError。因此,在从字典中取元素时需要考虑key不存在的情况。
info = {}
info['name'] = 'jay'
info['age'] = 20
info['python'] = 'hahaha'
if('a' in info):
print(info['a'])
else:
print('no key named \'a\'')可以用key in dict这种形式来判断Key是否存在于dict中。也可以用dict.get(key)函数来获取在该dict中key对应的value值。但是如果key不存在,该函数会抛出异常。所以我们需要为返回值设置默认值。
info = {}
info['name'] = 'jay'
info['age'] = 20
info['python'] = 'hahaha'
val = info.get('a',-1)
if(val!=-1):
print(info['a'])
else:
print('no key named \'a\'')将dict.get(key,default)的第二个参数设置为一些非法值,然后根据函数返回值即可判断字典中是否有该key。
- 删除字典中的元素可以用pop函数和del函数。例如:
info = {'name':'jay','age':20,'python':'hahaha'}
print(info.pop('name'))
#jay
print(info)
#{'python': 'haha', 'age': 20}
del info['python']
print(info)
#{'age': 20}其他注意点:
python多变量在同一行进行赋值可以这样写:
a,b,c=1,2,3python的print函数中的逗号,比如:
print(1,2,3)输出结果为:
1 2 3
在python中如何使print输出不换行
Python 2:使用print后加一个逗号:print 'hello',
Python 3:输入参数end:print('hello', end='')
python print函数不输出多余空格:
for i in range(6):
for j in range(i):
print('*', end='')
print()
输出结果为:
*
**
***
****
*****
但是在python的代码中用end=''的时候,需要在文件的开头第一行添加这条语句:from __future__ import print_function。如果import这个库的语句不在第一行就会出现下面的这种错误。
SyntaxError: from __future__ imports must occur at the beginning of the file
如果文件开头第一行为# coding: utf-8,那么下面import的第一个库必须是上面的这个库才不会导致end=''报错。如果有多条import语句,上面这条语句也必须放在所以import语句的最前面。
出现IndentationError: unindent does not match any outer indentation level错误都是代码缩进的问题。
python中if name == ‘main’: 的解析
模块是对象,并且所有的模块都有一个内置属性 name。一个模块的 name 的值取决于您如何应用模块。如果 import 一个模块,那么模块__name__ 的值通常为模块文件名,不带路径或者文件扩展名。但是您也可以像一个标准的程序样直接运行模块,在这种情况下, name 的值将是一个特别缺省”main“。
9. Reference
http://blog.csdn.net/fanhuajames/article/details/8781977
http://www.cnblogs.com/coser/archive/2011/12/14/2287739.html
http://www.jb51.net/article/54640.htm