目录
1. 基于最大间隔分隔数据
2. SVM应用的一般框架
3. SMO高效优化算法
3.1. 应用简化版SMO算法处理小规模数据集
4. 利用完整的Platt SMO算法加速优化
5. 在复杂数据上使用核函数
5.1. 利用核函数将数据映射到高维空间
5.2. 径向基函数
5.3. 在测试中使用核函数
基于最大间隔分隔数据
支持向量机的优缺点:
- 优点:泛化错误低,计算开销不大,结果易解释。
- 缺点:对参数调节和核函数的选择敏感,原始分类器不加修改仅适用于处理二类问题。
- 适用数据类型:数值型和标称型数据
%run notLinSeperable.py

SVM应用的一般框架
SVM的一般流程
- 收集数据:可以使用任意方法。
- 准备数据:需要数值型数据。
- 分析数据:有助于可视化分隔超平面。
- 训练算法:SVM的大部分时间都源自训练,该过程主要实现两个参数的调优。
- 测试算法:十分简单的计算过程就可以实现。
- 使用算法:几乎所有分类问题都可以使用SVM,SVM本来是一个二分类器,对多类问题应用SVM需要代码做一些代码。
SMO高效优化算法
SMO表示序列最小优化(Sequential Minimal Optimization) 。Platt的SMO算法是将大优化问题分解为多个小优化问题来求解(分治思想)。此外,SMO算法的求解时间很短 。
SMO算法目标:求出一系列$\alpha$和b,一旦求出$\alpha$,就容易计算出权重向量w并得到分割超平面。
SMO算法工作原理:每次循环中选择两个$\alpha$进行优化处理。一旦找到一对合适的$\alpha$,那么就增大其中一个同时减少另一个。这里的“合适”就是指两个alpha必须要符合一定条件,条件之一为这两个$\alpha$必须要在间隔边界之外,第二个条件是这两个$\alpha$还没有进行过区间化处理或不在边界上。
应用简化版SMO算法处理小规模数据集
Platt SMO算法中的外循环确定要优化的最佳$\alpha$对。而简化版会跳过这一部分,首先在数据集上遍历每个$\alpha$,然后在剩下的$\alpha$集合中随机选择另一个$\alpha$,从而构建$\alpha$对。有一点很重要,即需要同时改变两个$\alpha$ ,是因为满足一个约束条件:
由于改变一个$\alpha$可能会导致该约束条件失效,因此我们总是同时改变两个$\alpha$。
import svmMLiA
import numpy as np
dataArr, labelArr = svmMLiA.loadDataSet('testSet.txt')
#dataArr
#labelArr 分类的结果是-1和1,而不是0和1
SMO函数的伪代码如下:
创建一个$\alpha$向量并将其初始化为0的向量
当迭代次数小于最大迭代次数时(外循环)
对数据集中的每个数据向量(内循环):
如果该数据向量可以被优化:
随机选择另外一个数据向量
同时优化这两个向量
如果两个向量都不能被优化,退出内循环
如果所有向量都没被优化,增加迭代数目,继续下一次循环
reload(svmMLiA)
<module 'svmMLiA' from 'svmMLiA.pyc'>
#b, alphas = svmMLiA.smoSimple(dataArr, labelArr, 0.6, 0.001, 40)
b
matrix([[-7.41392199]])
alphas[alphas>0]
matrix([[ 1.00268663e-01, 6.55068337e-02, 4.31055668e-02,
3.38807426e-01, 2.77555756e-17, 1.77307123e-01,
4.76909718e-01, 6.93889390e-18, 3.16137333e-03,
1.73472348e-18]])
np.shape(alphas[alphas>0])
(1, 10)
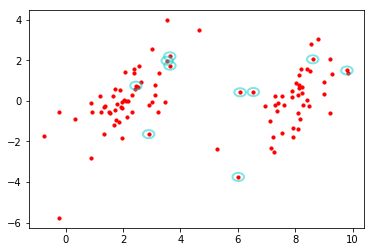
#输出支持向量
for i in range(100):
if alphas[i] > 0.0:
print dataArr[i], labelArr[i]
[3.542485, 1.977398] -1.0
[8.610639, 2.046708] 1.0
[3.634009, 1.730537] -1.0
[3.628502, 2.190585] -1.0
[2.450939, 0.744967] -1.0
[2.893743, -1.643468] -1.0
[6.080573, 0.418886] 1.0
[6.016004, -3.753712] 1.0
[6.543888, 0.433164] 1.0
[9.803425, 1.495167] 1.0
dataMat = np.mat(dataArr)
#dataMat[:,0].flatten().tolist()[0]
import matplotlib.pyplot as plt
from matplotlib.patches import Circle
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(dataMat[:,0].flatten().A[0], dataMat[:,1].flatten().A[0], s=10, c='red')
<matplotlib.collections.PathCollection at 0x8c751b0>
#坐标表示要画圈的地方,第二个参数表示圈的大小,faceclolor表示,edgecolor表示圈的颜色值,linewidth表示圈的线条粗细,alpha表示颜色深浅
for i in range(100):
if alphas[i] > 0.0:
circle = Circle((dataArr[i][0], dataArr[i][1]), 0.2, facecolor='none', edgecolor=(0,0.8,0.8), linewidth=2, alpha=0.5)
ax.add_patch(circle)
#ax.scatter(dataMat[:,0].flatten().tolist()[0], dataMat[:,1].flatten().tolist()[0], s=10, c='red')
plt.show()
利用完整的Platt SMO算法加速优化
Platt SMO算法是通过一个外循环来选择第一个$\alpha$值,并且其选择过程会在两种方式之间交替:一种方式是在所有数据集上进行单遍扫描 ,另一种方式则是在非边界$\alpha$中实现单遍扫描。非边界$\alpha$是那么不等于0边界0或C的$\alpha$值。对整个数据集的扫描很容易,而实现非边界$\alpha$值扫描时,首先需要建立这些$\alpha$值的列表,然后再对这个表进行遍历。同时该步骤会跳过那些已知不变的$\alpha$值。
reload(svmMLiA)
<module 'svmMLiA' from 'svmMLiA.pyc'>
dataArr, labelArr = svmMLiA.loadDataSet('testSet.txt')
b, alphas = svmMLiA.smoP(dataArr, labelArr, 0.6, 0.001, 40)
L==H
L==H
L==H
j not moving enough
L==H
L==H
L==H
L==H
L==H
L==H
j not moving enough
L==H
L==H
j not moving enough
L==H
L==H
L==H
L==H
L==H
j not moving enough
fullSet, iters: 0 i:99, pairs changed 6
iteration number: 1
j not moving enough
non-bound, iters: 1 i:0, pairs changed 0
j not moving enough
non-bound, iters: 1 i:3, pairs changed 0
j not moving enough
non-bound, iters: 1 i:4, pairs changed 0
j not moving enough
non-bound, iters: 1 i:17, pairs changed 0
j not moving enough
non-bound, iters: 1 i:18, pairs changed 0
j not moving enough
non-bound, iters: 1 i:25, pairs changed 0
j not moving enough
non-bound, iters: 1 i:46, pairs changed 0
non-bound, iters: 1 i:55, pairs changed 0
non-bound, iters: 1 i:94, pairs changed 0
iteration number: 2
j not moving enough
j not moving enough
j not moving enough
j not moving enough
j not moving enough
j not moving enough
j not moving enough
L==H
j not moving enough
j not moving enough
L==H
j not moving enough
j not moving enough
L==H
L==H
j not moving enough
fullSet, iters: 2 i:99, pairs changed 0
iteration number: 3
reload(svmMLiA)
<module 'svmMLiA' from 'svmMLiA.pyc'>
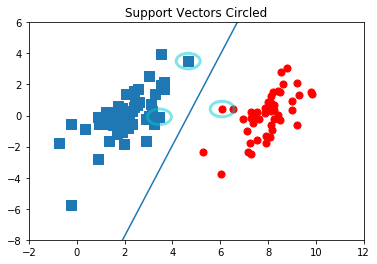
ws = svmMLiA.calcWs(alphas, dataArr, labelArr)
ws
array([[ 0.65307162],
[-0.17196128]])
dataMat = np.mat(dataArr)
dataMat[0] * np.mat(ws) + b
matrix([[-0.92555695]])
labelArr[0]
-1.0
dataMat[2] * np.mat(ws) + b
matrix([[ 2.30436336]])
labelArr[2]
1.0
dataMat[1] * np.mat(ws) + b
matrix([[-1.36706674]])
labelArr[1]
-1.0
%run plotSupportVectors.py
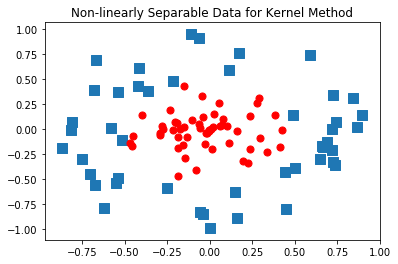
在复杂数据上使用核函数
在复杂数据上我们可以使用核函数(kernel) 来将数据转换成易于分类器理解的形式。其中,径向基函数(radial basis function) 是一种最流行的核函数。
利用核函数将数据映射到高维空间
对于复杂的数据,我们可以将数据从一个特征空间映射到另一个特征空间。在新的空间下,我们可以很容易利用已有工具对数据进行处理。数学家们喜欢将这个过程称为从一个特征空间到另一个特征空间的映射 。通常情况下,这种映射将低维特征空间映射到高维特征空间。
我们可以把核函数想成一个包装器(wrapper) 或者是 接口(interface) ,它能把数据从某个很难处理的形式转换成为另一个较容易处理的形式。
SVM优化中一个特别好的地方是,所有运算可以写成内积(inner product) 的形式。将内积替换成核函数的方式被称为核技巧(kernel trick) 或 核“变电”(kernel substation) 。
径向基函数
径向基函数是一个常用的核函数,它是一个采用向量作为自变量的函数,能够基于向量距离运算输出一个标量。这个距离可以是从<0,0>向量或者其他向量开始计算的距离。径向基函数的高斯版本如下:
$\sigma$是用户定义的用于确定到达率(reach) 或者说函数跌落到0的速度参数。
%run plotRBF.py
在测试中使用核函数
reload(svmMLiA)
<module 'svmMLiA' from 'svmMLiA.pyc'>
#svmMLiA.testRbf()
reload(svmMLiA)
<module 'svmMLiA' from 'svmMLiA.pyc'>
#svmMLiA.testDigits(('rbf', 20))